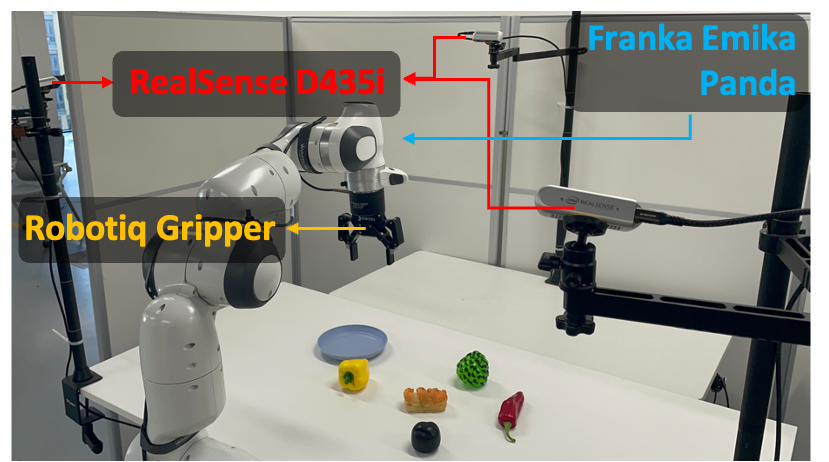
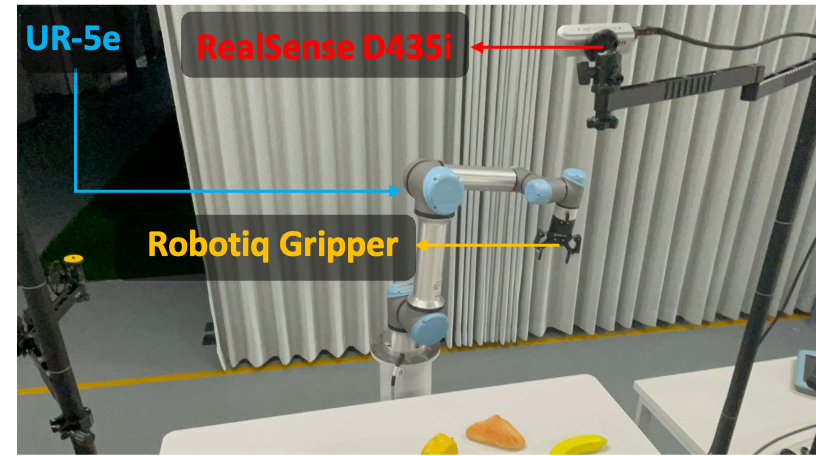
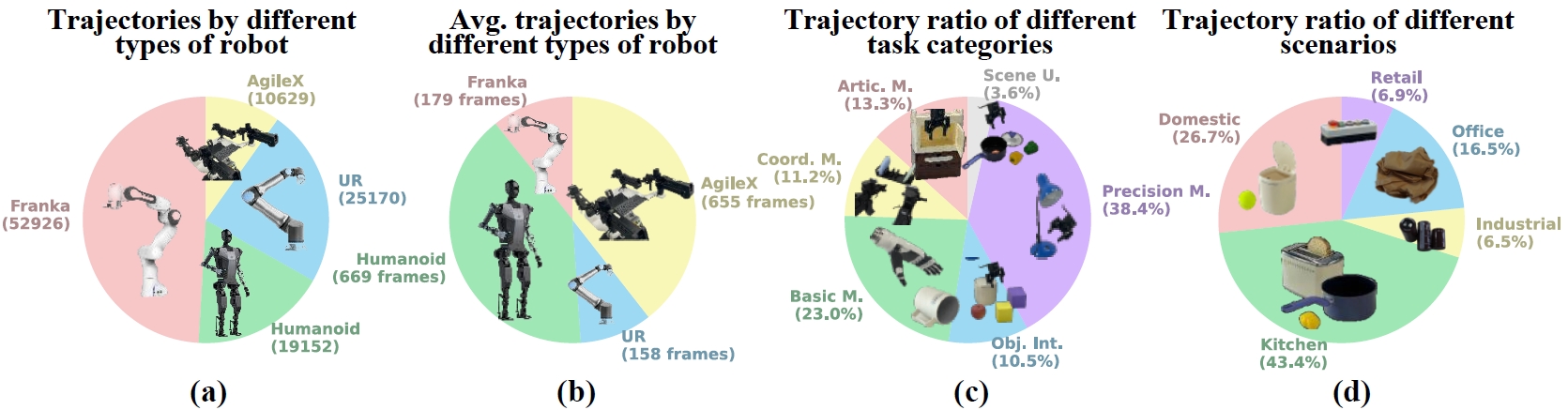
Dataset Overview. (a) the total trajectory numbers categorized by different types of robots, (b) average trajectory lengths (frames) categorized by different types of robots, (c) trajectory ratio of different task categories (Artic. M.: Articulated Manipulations; Coord. M.: Coordination Manipulations; Basic M.: Basic Manipulations; Obj. Int.: Multiple Object Interactions; Precision M.: Precision Manipulations; Scene U.: Scene Understanding), and (d) trajectory ratio of different scenarios.
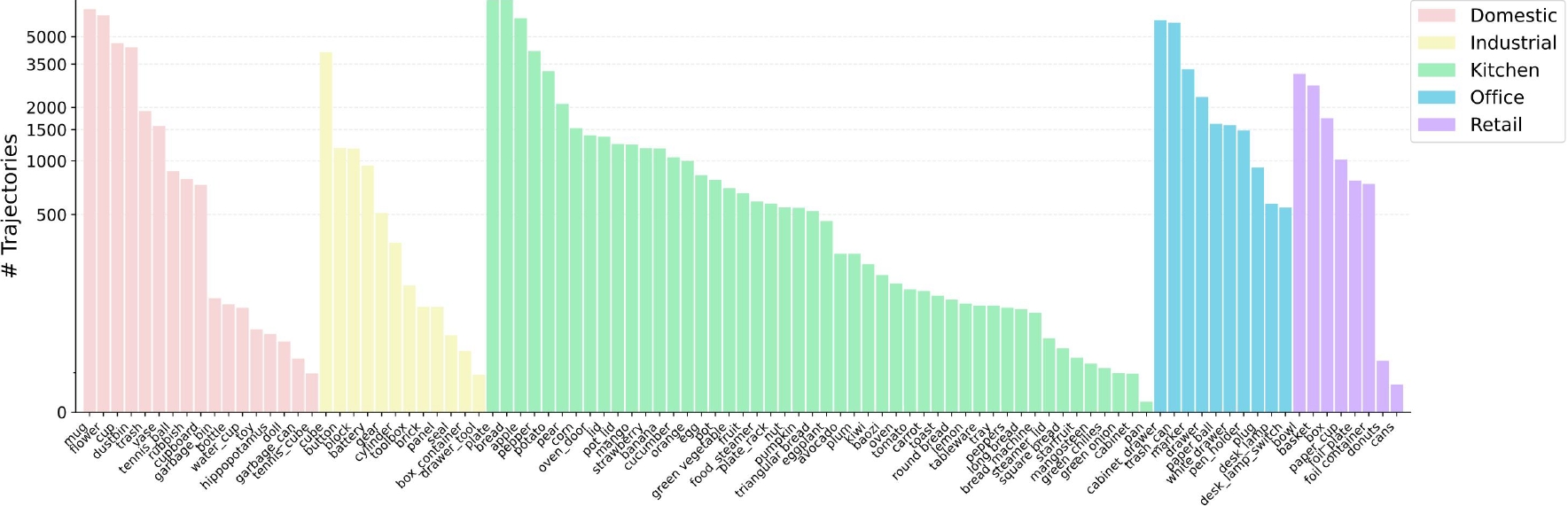
Distribution of objects in RoboMIND, categorized as domestic, industrial, kitchen, office, and retail.
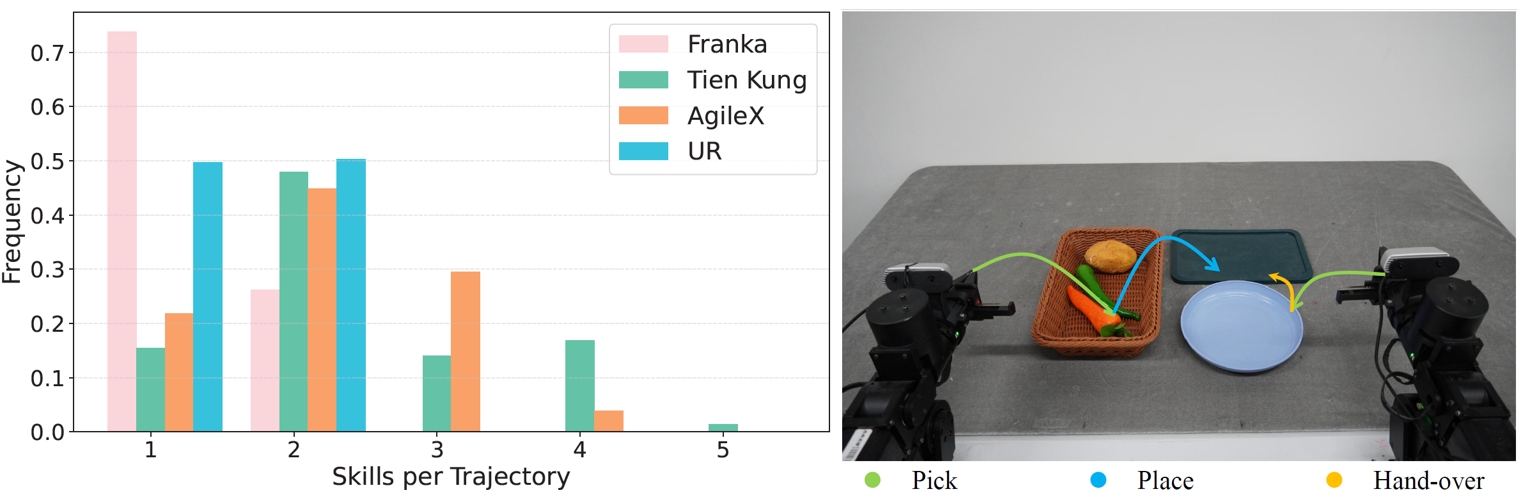
Left: Skill number distribution histogram across tasks for each embodiment. We observe that over 70% of the Franka tasks involve only a single skill, while over 75% of the Tien Kung and AgileX tasks involve two or more skills, indicating that these dual-arm tasks are mostly long-horizon tasks. Right: We visualize the AX-PutCarrot task with the AgileX robot, which involves three different skills.
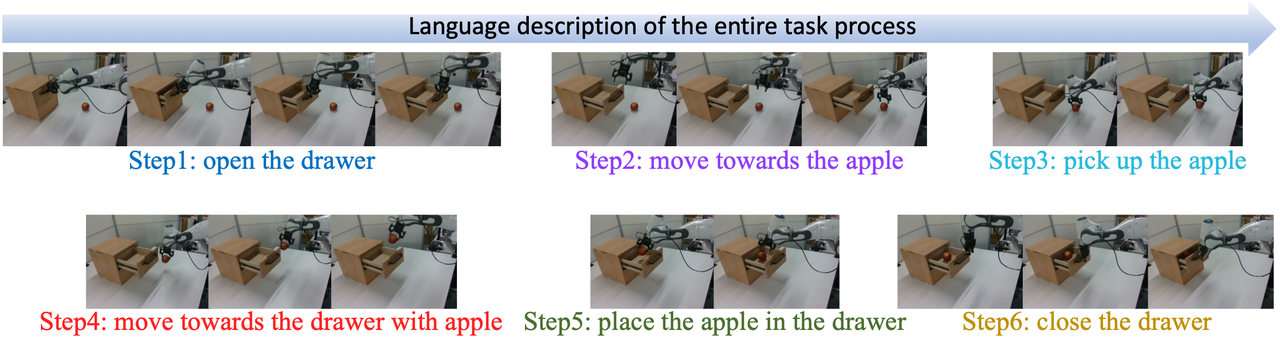
Language Description Annotation. We provide refined linguistic annotations for 10,000 successful robot motion trajectories. The video of the robotic arm placing the apple in the drawer is divided into six segments using Gemini. The language descriptions provided for each segment were initially generated by Gemini and subsequently refined through manual revision.
Visualization of failed data collection cases. We present two examples of failure from Franka and AgileX. In the FR-PlacePlateInPlateRack task (second row), the Franka arm fails to align with the slot, causing the plate to slip due to operator interference. In the AX-PutCarrot task (fourth row), the AgileX gripper unexpectedly opens, dropping the carrot. These failure cases were filtered out during quality inspection to maintain dataset quality.